


آکیلیش کومار ، معمار پردازنده های سری اسکایلیک-اسپی اینتل، امروز در پستی که در وبلاگ شخصی اش منتشر کرد از معماری مش ( Mesh )جدید اینتل برای پردازنده های با بستر مقیاسپذیرسری زئونخبر داد.
پردازنده های با بستر مقیاسپذیر اینتل، در واقع تغییر نام تجاری خط تولید پردازنده های محبوب سری زئون است و با توجه به استفاده ی مکرر اینتل از دایپردازنده های بهینهشده برای سرور، در خط تولید پردازنده های سرور و کامپیوتر های رومیزی سطح بالا، این معماری جدید توانسته است راه خود را به سری جدید پردازنده ی اسکایلیک-ایکس باز کند.
مقالههای مرتبط:
توپولوژی شبکهای جدید اینتل برای رقابت با تکنولوژی اینفینیتی فبریکشرکت AMD معرفی شده است. تکنولوژی اینفینیتی فبریک در پردازندههای سری رایزن، ترد ریپر و اپیک شرکت AMD وجود دارد. در ادامه به مقایسهی این دو طراحی میپردازیم.
دورهی باسهای حلقهای اینتل
کار اصلی پردازنده ، پردازش داده است که برای این کار به جریان داده بین عناصر اصلی پردازنده نیاز است. بیت هایی که نماینده ی صفر و یک هستند، توسط سیم هایی در ابعاد نانو ،با سرعت میلیاردها سیکل ساعت بر ثانیه داخل پردازنده جابجا می شوند. انتقال داده بین عناصر اصلی یک پردازنده مانند هسته ، حافظه و کنترلکنندههای ورودی و خروجی، یکی از سخت ترین چالش های پیش روی طراحان پردازنده است.
انتقال داده بهصورت کارآمد تأثیر بسیار زیاد و مستقیمی بر کارایی دارد و از آنجایی که انتقال داده به توان احتیاج دارد، در مصرف توان نیز بسیار تأثیرگذار است. کاهش مصرف توان هم باعث تولید گرمای کمتر توسط پردازنده می شود. در عوض اتلاف انرژی، اتصال های بهینهشده به معمار های کامپیوتر اجازه می دهد این توان را در بخش های مهم تری مانند پردازش داده مصرف کنند. در سال های گذشته تکنیک های زیادی برای انتقال داده بین هسته های پردازنده ها استفاده شده؛ ولی معماری حلقه ای اینتل در نسل های گذشته ی پردازنده های این شرکت استفاده شده است.
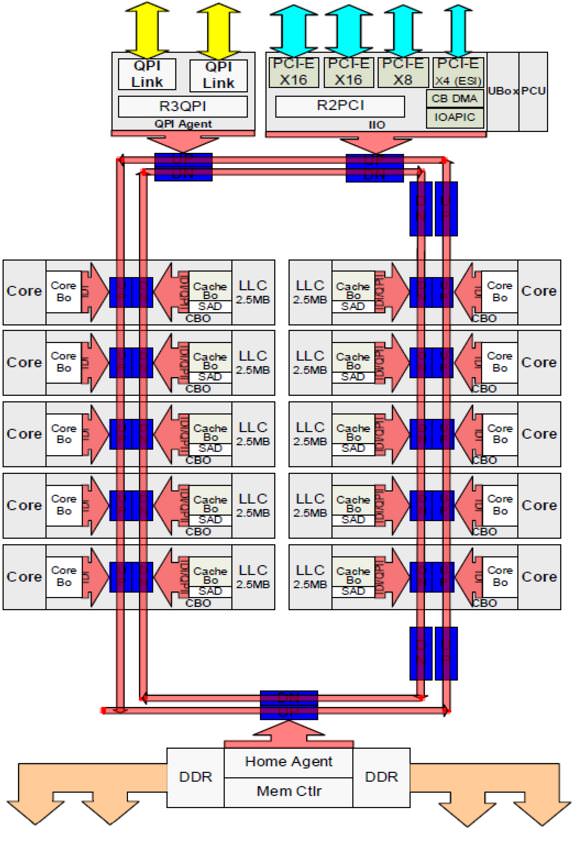
باس حلقه ای اینتل که در شکل بالا در یک دای سری برادولاز نوع کم هسته یا بهطور مختصر ( LLC) نشان داده شده، اجزا مختلف پردازنده را با یک باس دوطرفه - که با رنگ قرمز نشان داده شده است - به یکدیگر متصل می کند. دای از نوع LLCاز یک باس تک حلقه بهره می برد که دادهها را با سرعت یک سیکل ساعت بین دو هسته مجاور جابجا می کند. طبیعتا جابجایی داده به هسته های دورتر تعداد سیکل بیشتری مصرف می کند و در نتیجه تأخیر انتقال نیز بیشتر می شود. برای مثال انتقال داده به دورترین هسته، ۱۲ سیکل ساعت طول می کشد. از آنجایی که باس دوطرفه است، مسیریابی داده برای پیدا کردن کوتاه ترین مسیر بین دو هسته را میسر می کند.
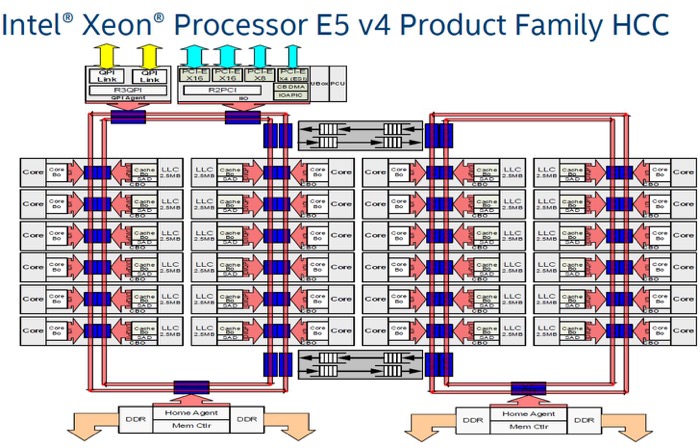
معماری های با تعداد هسته های بالا یا بهاختصار ( HCC) اشکالات این رویکرد را مشخص می کنند. برای افزایش تعداد هسته ها و کش ها، دای های HCCاز باس حلقه ای دوتایی بهره می برند. ارتباط بین دو حلقه از طریق یک سوییچ بافردار برقرار می شود (در شکل بین دو حلقه در بالا و پایین). عبور از سوییچ هزینه ای برابر با ۵ سیکل ساعت دارد؛ که با توجه به تأخیر جابجایی اطلاعات در داخل هر حلقه، عملا این معماری امکان مقیاس پذیری بالایی ندارد. تأخیر ارتباط بین هسته ها با بیشتر شدن تعداد هسته ها افزایش می یابد و کاهش کارایی را به دنبال دارد. برای جبران کاهش کارایی می توان فرکانس را افزایش داد که افزایش فرکانس هم باعث افزایش توان مصرفی و تولید حرارت بیشتر می شود.
معماری مش
اینتل معماری مش را برای اولین با در سری پردازنده های نایتز لندینگمعرفی کرد، ولی استفاده از این معماری برای پردازنده های سرور و کامپیوتر های رومیزی سطح بالا، سطح جدیدی از بهره وری اتصالات و در نتیجه افزایش کارایی را به همراه خواهد داشت. علاوه بر اتصالات، ویژگی جدید این معماری جابجایی کنترلرهای DDR4به سمت راست و چپ دای است؛ بر خلاف معماری های حلقه ای که در قسمت پایین قرار داشت.
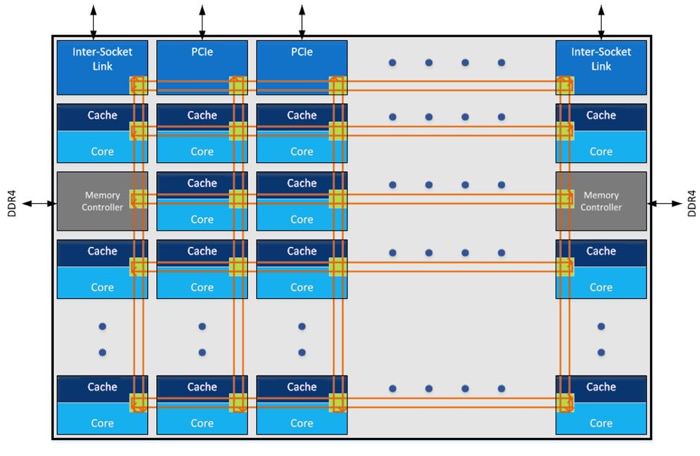
اینتل در توپولوژی مش جدید، هسته ، کش، حافظه و کنترلر های ورودی و خروجی را در ردیف های افقی و عمودی به یکدیگر متصل کرده است. نکته ی قابل توجه عدم وجود سوییچ های بافردار (که یکی از عوامل کندکننده ی اتصالات بود) است. وجود سوییچ های واقع در تقاطع اتصالات، امکان ارتباط مستقیم و زمانبندی هوشمند برای پیدا کردن کوتاه ترین مسیر بین اجزا را فراهم کرده است. همچنین یک طراحی حلقه مانند در اتصالات وجود دارد که امکان ایجاد زمان بندی بهینه در مسیر داده را فراهم می کند.
قابلیت جابجایی داده بهصورت پله ای بین هسته ها، امکان مسیریابی پیچیده تر ولی مؤثر بین عناصر دای را امکانپذیر می کند. طبق گزارش اینتل، معماری حلقه ی جدید پهنای باند را هم افزایش داده است که در نتیجه سرعت انتقال داده بین هسته ها و کش هایی که آنها را تغذیه می کنند، افزایش پیدا کرده است. معماری مش ترافیک داده ی ورودی و خروجی حافظه ی اصلی را هم کنترل می کند و باعث افزایش بازدهی و کاهش تأخیر رم نیز شده است.
در قسمت بالای دای، جریان داده از کنترلر های PCIدر کنار دو کانال ارتباطی بین سوکت برقرار است. کانال های ارتباطی بین سوکت، جریان داده بین تعداد پردازنده های بیشتر از دو عدد را برای تنظیمات مخصوص شبکه مدیریت می کنند. در گذشته اینتل از تکنولوژی ( QPI)برای ارتباط بین سوکت ها استفاده می کرد؛ ولی شایعات خبر از استفاده از کانال ارتباطی جدید در سری پردازنده ی جدید اسکایلیک در مدل سرور می دهند. اینتل بهطور دقیق فرکانس کاری معماری مش جدید را اعلام نکرده است،؛ ولی طبق گزارش اینتل، فرکانس و ولتاژ کاری پایین تری نسبت به معماری حلقه دارد و در عین حال پهنای باند و تأخیر کمی هم دارد.
از سری اسکایلیک-ایکس چه میدانیم؟
اینتل تصویری از دای معماری HCCخود که در سری اسکایلیک-ایکس استفاده شده، منتشر کرده است. اینتل در سری زئون نیز از معماری مش مشابهی استفاده کرده بود.

در تصویر بالا، بهراحتی می توان کنترلر های DDR4را در سمت راست و چپ دای (ردیف دوم سمت چپ و راست) مشاهده کرد. اما درحالیکه به نظر می رسد این دای شامل ۲۰ هسته است، تنها ۱۸ هسته دارد. این تعداد هسته تا اینجا بیشترین تعداد هسته ی موجود در سری اسکایلیک-ایکس بوده است.
نمودار مش اینتل مشخص می کند که اتصالات درون مش در سمت راست هر هسته قرار دارد ولی طبق تصویر دای، این اتصالات در تمام هسته ها در سمت راست قرار ندارد. برای مثال در سمت چپ ترین ستون، اتصالات درون مش در محدوده ی بالا سمت راست هسته واقع شده است؛ ولی در سمت راست ترین ستون، این اتصالات در جهت قرینه یعنی بالا سمت چپ قرار دارند. این روش چینش اتصالات در فاصله ی بین هسته ها تأثیر مستقیم دارد و در نتیجه برای انتقال داده بهصورت افقی به تعداد سیکل های بیشتری نیاز است. برای مثال برای انتقال داده بهصورت عمودی، به ازای هر سطر به یک سیکل نیاز است؛ ولی برای انتقال داده بهصورت افقی از ستون دو به سه، به تعداد سیکل بیشتری نیاز است. باید در آینده منتظر انتشار جزئیات بیشتری از سوی اینتل باشیم.
در هر صورت، معماری مش امکان مقیاس پذیری بی نظیری نسبت به معماری قبلی فراهم کرده است و با توجه به این که اینتل از معماری حلقه ای در چندین نسل از پردازنده هایش استفاده کرد، انتظار می رود در سال های آینده از معماری مش در پردازنده های این شرکت استفاده شود. این معماری به اینتل امکان افزایش تعداد هسته ی پردازندههایش، بدون افزایش تأخیر و توان مصرفی را می دهد.
از AMD چه خبر؟
صحبت از معماری های اینتل بدون مقایسه با آخرین معماری AMDناقص است. AMDهم یک اتصال جدید از نوع اینفینیتی فبریک طراحی کرده که ورژن بهینهشدهی هایپر ترانسپرت استکه در میکرومعماری ذن به کار می رفت. خوشبختانه اطلاعات بیشتری درباره اتصالات برون هسته ای AMDدر اختیار داریم.

AMDدر سری پردازنده های ذن، روش متفاوتی برای طراحی پردازنده انتخاب کرده است. میکرومعماری ذن از بلوکهای ۴ هسته ای که CPU Complexیا بهاختصار CCXنامیده می شوند، بهره می برد. AMDهر بلوک را با استفاده از کش های ۸ مگابایتی به ۴ بخش تقسیم می کند؛ هر هسته با میانگین تأخیر مشابه به این کش های L3دسترسی دارد. با استفاده از ۲ بلوک CCXیک پردازنده ی ۸ هسته ای رایزن 7ساخته می شود (بلوکهای نارنجی در تصویر بالا). این بلوک ها توسط یک اتصال از نوع اینفینیتی فبریک به یکدیگر متصل می شوند. CCX-ها کنترلر حافظه ی مشترکی دارند. پردازنده اصلی که در واقع دو پردازنده ی ۴ هسته ای است، توسط یک مسیر اینفینیتی فبریک با یکدیگر ارتباط برقرار می کنند. اینفینیتی فبریک، یک مسیر ارتباطی ۲۵۶ بیتی دوطرفه است که وظیفه ی جابجایی ترافیک بین بلوک ها را بر عهده دارد.
هرچند تأخیر ارتباط هسته ها با یکدیگر در یک CCXبه دلیل استفاده از حافظه مشترک یکسان است؛ واکشی داده از سایر بلوک ها با تأخیر عبور از اینفینیتی فبریک همراه است. ارتباط بین تِرِدهایی که در بلوک های مختلف قرار دارند هم از این تأخیر رنج می برد. معماری AMDبرتری زیادی نسبت به معماری حلقه ی اینتل داشت؛ زیرا AMD بهراحتی می توانست با افزایش تعداد بلوک ها در یک تراشه، تعداد هسته ها را افزایش بدهد. انتظار می رود پس از معرفی معماری مش اینتل، پردازنده های این شرکت نسبت به پردازنده های AMDبرتری پیدا کنند؛ ولی این نکته را هم باید در نظر گرفت که بهینهسازیهای نرم افزاری می تواند بسیاری از مشکلات تأخیر اینفینیتی فبریک را رفع کنند.
با اندازهگیری تأخیر اینفینیتی فبریک در پردازنده مدل AMD Ryzen 5 1600X،متوجه می شویم که تأخیر اینفینیتی فبریک به فرکانس مموری وابسته است. از طرفی در تأخیر معماری حلقه ای اینتل با افزایش فرکانس مموری کاهش خاصی در تأخیر مشاهده نشد. باید تا تست پردازنده های سری اسکایلیک صبر کنیم تا تأثیر فرکانس مموری بر تأخیر این معماری جدید را بسنجیم.
رقابت همچنان ادامه دارد
با معرفی معماری های جدید هر دو شرکت که هر دو نسبت به نسل های قبل از خود پیشرفت های چشم گیری دارند، رقابت همچنان برای نسل های آینده ادامه دارد.
هر معماری نقاط قوت و نقاط ضعف مربوط به خود را دارد و بهترین راه برای مقایسه، مقایسه
ی آن
ها بعد از پیاده
سازی روی سیلیکون است.
مشاهده پست مشابه :
یوبی سافت و چالش مصر باستان! – یوبی سافت چگونه مصر باستان را طراحی کرد ؟